При археологических раскопках древних файлов обнаружилась заброшенная SQLite база данных (далее - бд) несостоявшегося развлекательного приложения гороскопов. Мне стало любопытно, насколько быстро можно написать к ней маппер. Маппинг сам по себе полон подводных камней и нюансов, что делает его плохо подходящим для велосипедостроения, но в формат аналитического блога такие эксперименты логично вписываются.
Статья целиком исследовательская и черновой вариант маппера имеет множество недостатков - это всего лишь эксперимент, не более, да и не со всеми видами связей удалось поэкспериментировать.
В базе данных обнаружилась такая схема:
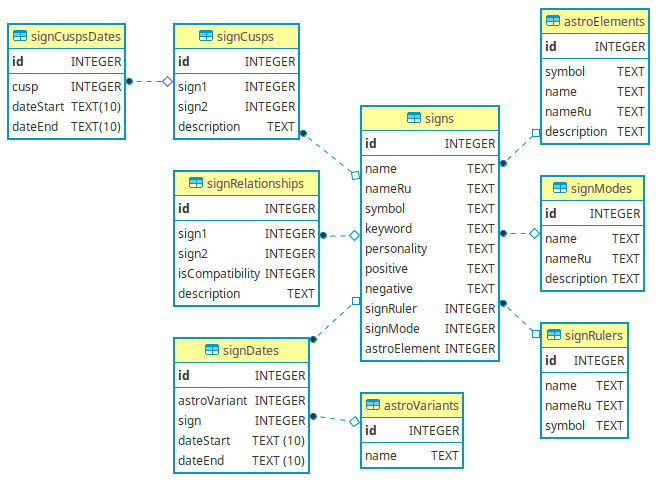
Читатели девлога планировщика вспомнят, как из-за перехода на новую модульную Java 9 пришлось срочно делать замену для ORMLite. Из-за недостатка времени весь парад костыльных решений определялся уже существующим кодом, затирая эволюцию: для упрощения кода приложения нужно двигаться в обратную эволюции сторону, что сделать проблематично без наблюдения развития архитектуры с нуля. Мне захотелось поэкспериментировать с самыми простыми задачами, поскольку маппинг относится к классу проблем для которых упрощение может быть важнее возможностей или изящной игры с хитросплетениями паттернов. NIH-синдром не работает в языках с ограниченным или узкоспециализированным набором библиотек: чем их меньше, тем меньше шанс подобрать решение под свою задачу. Реалии суровы и рождение велосипедов - очень часто лишь вопрос времени.
Сомнительный смысловой характер бд компенсируется её техническими особенностями, чрезвычайно удобными для маппинга:
- Именование таблиц во множественном числе упрощает построение некоторых связей, например, для наиболее проблемной ситуации - связи один-ко-многим. При описании связи нужно идентифицировать поле сущности, к которому она применяется. Связь уникальна и по типу поля сделать это не выйдет, а имя поля нигде не хранится и в описании таблицы на стороне "одного" его нет. Если же имя поля совпадает с названием таблицы, то эта проблема решается, да и имена вполне логичны - таблица действительно хранит множество строк. Но рождается разброс между ед.ч и мн.ч, для унификации взят более общий случай. С другой стороны, мн.ч. создает проблему для кодогенерации в нетривиальном переводе имени таблицы в ед.ч. имя сущности. Простая обрезка окончания не покрывает множество случаев, например, ties -> ty и т.п. Можно, конечно же, указывать столбцы и вручную строковыми значениями, но это не особо технологичный способ, хотя бы и рабочий.
- Имена таблиц и столбцов приведены в lowerCamelCase, что облегчает их соответствие полям класса.
- Везде есть первичные ключи, многие операции упрощаются.
Здесь нужно отметить, что не каждая база данных позволяет свободно оперировать регистрозависимыми именами таблиц, а если и позволяет, то могут криво работать инструменты, причем поведение может различаться в зависимости от операционной системы.
Выходит, что бд уже частично синхронизирована с кодом, только и только поэтому она и была выбрана для экспериментов. На всякий случай лишний раз напомню об Эффекте Барнума и развлекательном характере бд: нельзя относиться к ней серьезно, нас интересует лишь реализация маппинга, не более.
Для экспериментов я снова выбираю Groovy за счет удобного core api, да и в 3 версии появились try-with-resources, удобные для работы с бд. В рамках эксперимента выбор языка удобен, но из-за медленного запуска консольного скрипта частые обращения к бд сильно осложняются, а для такого приложения они могут потребоваться, например, для работы в связке с парсером или что-то в этом роде. Раз консольное приложение не выходит, то можно попробовать прикрутить JavaFX, получая в нагрузку еще один эксперимент. Вообще, изначально я планировал выбрать Dart, но они поставили в приоритет макось, что бывалого линуксоида заставляет идейно опечалиться.
Я не буду описывать построение приложения - задача тривиальна. Отмечу лишь несколько особенностей для связки Groovy и JavaFX:
- Использовал Groovy 3 и свежую (стабильную) версию JavaFX под Linux.
- При описании зависимостей для Grape нужен classifier, например @Grab(group='org.openjfx', module='javafx-fxml', version='13.0.2', classifier="linux"). Вероятно, через AST-трансформации или еще какие-трюки можно воспроизвести туториал на сайте OpenJFX, где на основе операционной системы он проставляется автоматически, ибо код просит классификатор в виде строковой константы, ругаясь на все остальное. Еще один вариант - сделать все отдельным скриптом, скачав либы под все системы и передавая нужные при запуске.
- Наследование главного класса от javafx.application.Application вызывает ошибку. Но можно использовать статический метод Application.launch.
- Нужно указать либы тулкита, да и все остальные зависимости, например, в скрипте запуска сделать export CLASSPATH, в котором пути к .jar-файлам из папки .grape, если она локальна и задается через -Dgrape.root. В таком случае груви никак не может знать где найти зависимости для приложения. Т.е. все заработало без modulepath
- Долгий запуск, порядка 30 секунд.
- Очень большое потребление памяти, в 2-3 раза выше в сравнении с нативной Java: 500-600 MiB. Скорее всего на сотню иди другую можно оптимизировать: попробовать отказаться от FXML, тем и т.п., но в данном случае мне нужна очень высокая скорость прототипирования, даже в ущерб производительности, да и JavaFX без FXML сильно теряет свои преимущества.
Вот такой вот прототип получился в итоге:

Ранее я не использовал Groovy для взаимодействия с SQLite, не знаю всех подводных камней и некоторые методы могу использовать не совсем корректно:
- Из-за опасения побочных эффектов я не буду использовать аннотирование для equals\hashcode или другие продвинутые аннотации, которых полным-полно в Groovy на самые разные случаи. Например, насколько я в курсе, нововведение 3-версии @NullCheck конфликтует с @Canonical + @Immutable и т.п.
- Не буду использовать в именах "репозиторий" и т.п., предпочитая универсальные "менеджеры".
- В листингах отсутствуют всяческие проверки для упрощения. Несмотря на то, что груви распечатывает содержимое переменных при провале утверждения assert (и делает это супер удобно, хотя иногда промахиваясь с форматированием) в некоторых случаях нужно очень информативное сообщение с разной дополнительной информацией.
- Отсутствует проверка статуса и валидация JDBC соединения.
- В Groovy можно обойтись без .class, но такая семантика может запутывать, поэтому буду по старинке.
- Не использую финализацию (final), кроме как для Groovy-свойств, чтобы отключить сеттер.
- Большей частью использую геттеры для унификации, хотя иногда могут просочиться и свойства - пока я не совсем с ними определился. Для работы в IDE и переносимости удобнее первые, для читаемости и кода - вторые, но смешение их такое себе, например, в новых версиях Groovy синтетический геттер дает ошибку в Mockito. Опасаясь подобных побочных эффектов, я все же буду вызывать геттеры для джавовского апи, хотя скорее всего свойства тоже безопасны.
- Конечно же, для маппинга есть опасность sql-инъекций. В билдер или в менеджер с билдером может прилететь вредоносная строка и поучаствовать в построении запроса, о чем нужно помнить, особенно это актуально для имен таблиц или столбцов. А раз дело касается безопасности, то нужно включать параноика и ко всем примерам ниже относиться лишь как к прототипным, описывающим общие концепции. Это лишь эксперимент, не более.
Как подсказывает википедия, маппинг - это определение соответствия данных между потенциально различными семантиками одного объекта или разных объектов. Раз речь идет о соответствии, то можно вспомнить отображение множеств и взять его за концептуальную модель кода.
В самом простом случае каждому элементу во множестве полей сущности поставится в соответствие столбец таблицы. Для простого конвертирования бд-типа в Groovy-тип или для отношения один-к-одному (в случае одинаковых имен) такое соответствие будет взаимно-однозначным (биективным), что реализуется простым конвертером.
Однако в случае более сложных, например, один-ко-многим на поле сущности может находиться список с объектами из совершенно другой таблицы, а для внедряемого Embedded-объекта несколько полей таблицы ставятся в соответствие одному полю сущности. Припоминая сюрьективное отношение можно даже придумать ситуацию, когда нескольким полям сущности будет соответствовать один столбец, например, дата в текстовой форме и в ZonedDateTime. Можно такое реализовать и через сеттер, но он будет зависим от другого поля, да и рефлексивное заполнение его может проигнорировать, либо через донастройку объекта, что не очень удобно.
Рассмотрим простую таблицу, в которой отметим:
- Вид связи
- Значение, которой должен возвратить маппинг для поля сущности.
- Значение из поля сущности, которое маппинг должен возвратить для операций с бд (вставка, обновление).
- Наличие связанной\транзакционной с сущностью вставки.
- Наличие связанного\транзакционного обновления.
Отношение один-к-одному можно рассмотреть по-разному. С одной стороны, оно может базироваться на объединении первичного и внешнего ключа. С другой стороны, оно может быть похоже на один-ко-многим и носить условный характер за счет обязательного наличия первичных ключей у всех таблиц для целей отображения или особенностей базы данных. Скорее всего, понятия реляционной модели будут несколько расходиться с ORM.
Для целей упрощения можно попытаться рассмотреть сложные связи как частный случай более простых. Например, если для многие-ко-многим создать отдельный класс-менеджер, работающий с таблицей, то при выборке его маппинг очень похож на поведение маппинга один-к-одному. С другой стороны, при запросе по id реализацию можно привести к один-ко-многим.
В случае полноценной реализации связи, как будет отмечено далее, запросто может возникнуть проблема циклической передачи зависимостей, когда для сборки маппера требуется другой маппер, а для сборки этого другого требуется первый, что исключает инжекцию в конструктор. Да и при запутанных зависимостях есть шанс получить иные проблемы, например, спрятанную утечку памяти, невалидное состояние объекта и т.п. Выходит, есть определенное различие между маппингом связи и маппингом объектов в этой связи, смотря на какой стороне связи этот маппинг происходит. Объектные понятия тут местами не слишком удобно перемешиваются с реляционными.
Если допустить, что результат запроса к бд можно привести к структуре ключ-значение, например, мапе, то рождается такая табличка:
| Тип маппинга | Маппер из бд | В бд | Связ. вставка | Связ. обновление |
|---|---|---|---|---|
| Тип бд в Groovy-тип | Groovy-тип (напр, Boolean) | Тип столбца, напр, Integer | - | - |
| Embedded-object | Embedded-object из Map<String, Object> | Map<String, Object> | - | - |
| Один-к-одному | Сущность | id внешнего ключа | + | + |
| Один-ко-многим | Список объектов по id внешнего ключа | - | + | + |
| Многие-ко-многим | Сущность | id внешнего ключа | + | + |
Маппер должен быть самым простым и нужен один класс, который бы охватывал все возможные случаи. Из таблицы видно, что наиболее универсальным типом будет Map<String, Object>, к тому же для один-ко-многим запросы идут совершенно к другой таблице, что в совокупности с возможным null в бд намекает на сочетание Optional и пустой мапки.
Связанные операции вставки и обновления могут по аналогии определять операции выборки - если вставку в другую таблицу будет всегда делать маппер, который за неё ответственен, то выборку он должен делать тоже, ибо эта таблица - только его ответственность. Это вводит идею делегирования в виде ассоциации мапперов. Т.е. в самом простом случае без JOIN при запросе findAll менеджер сущности делает запрос и передает id внешнего ключа другому менеджеру, который делает поиск по внешнему ключу и собирает сущность, отдавая его для установки в поле.
В таблице выше есть одна проблема - в ней рассматриваются отображение значений совместно с отображением связей. Для простого случая это может быть допустимым, но, например, ассоциация может быть двунаправленной и однонаправленной, в зависимости от наличия ссылок на друг друга у объектов. Внешний ключ же не несет такой информации. Эта проблема проявится в виде невозможности создания двунаправленной связи из-за сборки части объекта без самого объекта, а сам объект не собран из-за отсутствия частей. Можно, конечно же, извернуться и проставить обратные ссылки после сборки агрегата, например, через пост-методы, но при работе с бд маппер части будет бессилен что-то сделать с вложенным в часть агрегатом - ему нужен маппер для делегирования обновления или вставки, который невозможно создать из-за опять же циклических конструкторов: маппер требует маппера агрегата, а тот требует первый.
С другой стороны, это тот случай, когда сопротивляться архитектуре себе дороже. ORM обычно позволяют создавать любые классы связей, даже самые изощренные, позволяя вкладывать сущности друг в друга без какой-либо логики - кирпич как составная часть дома, или дом, как составная часть кирпича. Наличие ссылки позволяет обращаться к объекту, а значит и управлять им.
Такие конфликты плавно перетекают в UML и отношения объектов. При этом существует огромнейшее расхождение во мнениях, где агрегация, где композиция, а где что-то другое. Один посчитает композицию как часть-целое, где часть не может существовать отдельно, другой вспомнит, что существование в программе и существование в реальности вещи разные и отсутствие ссылок или внешней сборки это и есть композиция. Кто-то еще скажет, что в условной модели вообще возможно все, что угодно, вон в геймдеве в иерархиях классов игры камень это живое существо, а человек нет и все вполне работает и т.п.
Кроме того, выше не рассматривается отношение наследования, которого нет в бд. Несложно заметить, что все таблицы имеют первичные ключи, а значит все они могут быть описаны как уникальные сущности, наследуясь от неё. И это логично: при изменении размера идентификатора, например, с Integer на Long нужно будет изменять все классы, что дублирование кода. Однако таблицы у всех разные и стратегия наследования уже частично задана базой данных - отдельная табличка для класса, класс таблицы также может убирать дублирование кода наследованием. В этом случае появляется дублирование теперь уже не стороне бд, но с другими последствиями - изменение имени столбца вступает в конфликт с полем в классе-родителе, а изменение суперкласса и того хуже - правки огромного количества таблиц. С другой стороны, все логично - если объект перестает являться видом, то в отношении его ломаются все видовые правила, как это и происходит в реальности.
ORM предоставляют самые разные стратегии - могут использовать union, запихнуть все сущности в одну таблицу с null на полях или еще как извратиться. Создать аналог такому функционалу очень трудно или вообще неподъемно. Таким образом, отображаются простые значения, отношения самым разным способом и нужно принять решение - кто должен заниматься запросами в бд с учетом проблем выше. Задача упрощения подразумевает объединение в одном классе отображения простых значений и связей. Так как каждый маппер ответственен за свою сущность, то объединение или пересечение он сделать не сможет, ибо не знает о других таблицах и других мапперах. С другой стороны, он может делать запросы в пределах своей таблицы. Для простого случая выбор явно в пользу делегирования.
Недостатки такой схемы:
- Проблемность с JOIN, вернее его можно реализовать, но это потребует определенных усилий. В простом случае в маппинге происходит запрос, в случае JOIN извлекаются данные из полученной мапы и вызывается метод сборки из мапы. Изменяется структура запросов к бд, намекая на отдельные стратегии.
- Проблемность с двунаправленными связями, о чем уже упоминалось выше, а также со сложными связями вообще.
- С проблемой связей частично пересекается проблема с ограничениями целостности по внешним ключам, когда для разных видов связей id вставляемой строки вложенной сущности может как существовать в бд, так и нет, а значит эта вставка должна срабатывать либо до вставки основной сущности, либо после неё.
- N+1 и быстрый рост числа мелких запросов. Хотя большая их часть идет по внешнему ключу и скорее всего будут индексными, но это явно может сказаться на производительности. Конечно же, поведение мапперов можно сделать управляемым через разные флаги и получить что-то вроде lazy-загрузки.
- Универсальность обычно требует затирание типов, а это уже опасная ситуация. Может прилететь не то и не туда, при изменении api компилятор никак не обнаружит проблему.
- По невнимательности легко получить заблокированную бд: маппер открывает соединение и передает его другому мапперу, который это соединение не использует, а открывает новое, приложение ложится при конфликте чтения\записи.
- Легко получить объект в невалидном состоянии т.к. в каждом конкретном случае требуется донастройка маппера и легко что-то где-то случайно забыть.
- Необходимость дублирования методов - один для транзакционности, а другой без.
- Сторонним мапперам нужно передавать соединение, что снижает тестируемость, затрудняя сборку из простой мапы.
- Усложнение сборки самих мапперов из-за нужды в других мапперах. Хотя это и логично, а Groovy имеет режим статической проверки типов, которая перед запуском не дает настрелять себе в ногу, но в условиях чисто динамического языка сложная сборка может представлять большую проблему для последующих изменений. Кроме того, если таких сборок будет много, то можно получить еще и поломку всех конструкторов в иерархии при изменении базовых классов.
- Проблема сборки делает рефлексивное создание объекта более трудоемким и если в приложении есть простой сервис-менеджер, который инстанцирует на основе конфига и далее передает объект кому-то для сборки, то передача зависимостей через конструктор может сильно осложниться.
Некоторые недостатки сильно снижают тестируемость, например, если бы маппер собирал объект на основе только мапы, то никаких зависимостей от бд в нем бы не было. Если начать с реализации джойнов, то такой вариант возможен - менеджер сущности имеет список маппингов, в которых можно найти, например, связи один-к-одному или такой список может быть отдельным. Из связи можно узнать имя таблицы, а по ней сделать джойн. С другой стороны, это сильно снижает гибкость - один класс должен учитывать самые разные варианты, например, вставку списка объектов при связи один-ко-многим или нестандартные случаи. Когда-то очень давно я напоролся на коварный баг с джойном, при котором вместо id сущности подставлялся id внешнего ключа, перезаписывая его в мапе, но т.к. в первых нескольких сотен записей ключи совпадали, то баг не проявил себя сразу. Для простого приложения или для специфичной бд множество подобных запросов могут не повлиять на производительность, но они намного проще отлаживаются и более предсказуемы.
Можно попытаться понизить некоторые риски:
- Доступность мапперу любых запросов, в нем должно учитываться специфичность бд, его типов, билдер запросов и т.п., чтобы в случае проблем с производительностью или других ограничений просто переключиться в "ручной режим", игнорируя автоматические преобразования и вообще весь маппинг.
- В случае однозначного соответствия дополнительная проверка на совпадение имен столбцов и имен полей.
- Параметризация там, где это возможно.
- Ограничения в самой бд - не-null, дефолтные значения и т.п.
- Валидация объектов перед вставкой\обновлением и сразу после выборки. Однако дочерний класс может захотеть сделать вызов super и получить сущность в полузаполненном состоянии, тогда валидацию нужно отключать.
Последний момент кидает камень в огород валидации в контроллерах или в сервисах, которые имеют тенденцию оборачивать репозитории и проксировать все вызовы к ним. Операции маппера очень опасны и если не завязывать его на валидатор, то никак нельзя гарантировать, что в методы поступают и возвращаются валидные объекты. В простом приложении никаких сервисов нет или они создаются для более сложных случаев, которые не может решить простой репозиторий\менеджер, риск получения невалидного объекта чрезвычайно высок и тесная связь с валидатором может быть неплохим вариантом.
Так как примеры ниже упрощены, то может появится желание нашпиговать мапперами приложение. В простом случае это сработает, например, для такого простенького приложения гороскопов даже в случае изменений мапперы используются только в одном контроллере и их всегда можно переместить. Редкое использование не представляет высоких рисков. Но если маппер находится в сквозной логике, разбросан по всему приложению, то все не так просто.
Существуют разные мнения, к какому слою относить работу с бд. С одной стороны, SQL-запрос может содержать запутанные расчеты и сложную логику, а формирование подобного запроса другим классом потребовать раскрытия билдера, особенности бд и т.п. нюансов. Тогда бд очень тесно интегрируется с приложением и многочисленные методы достаточно сложно вынести в интерфейс, чтобы в случае смены источника с бд, например, на сеть, поменять все мапперы. Если принять, что интерфейс (или абстрактные методы) может создавать отношение пересечения, то это касается скорее очень общих условных контрактов. Контракты самих методов, их побочные эффекты для приложения, рантаймовые непроверяемые исключения могут запросто нарушаться, поэтому нельзя говорить о быстрой полноценной замене бд в сложной логике на что-то другое. Данные, возможно, и будут возвращаться те же, но приложение все равно будет работать иначе. Кроме того, код пишут люди, поэтому начинают действовать ограничения кратковременной памяти, определяя собой потолок абстракций, например, interface segregation principle вполне способен превратить понимание иерархии в ад, как и навигацию по ней.
С другой стороны, какую-либо часть методов - findAll, findById и т.п. все равно можно вынести в интерфейс работы с данными и получить хотя бы минимальную, но гибкость. Если импорты мапперов начинают распространяться по приложению, то это может быть сигналом для подстраховки: логика начинает завязываться на базу данных и нужно выделять интерфейс работы с абстрактными данными. В сложных случаях, конечно же, сделать это не выйдет, но в случае изменений нужно будет поломать лишь часть кода. Хотя это интуитивно, но я лишний раз решил напомнить об этом, хотя бы данная статья целиком экспериментальная и не предполагает боевого использования её кода, но все же.
Учитывая требования выше о возможности переключения на простые запросы, соберем сначала универсальные понятия, которые будут определять самую общую структуру классов для работы с бд, не зная ничего о маппинге:
- Особенности подключения
- Диалект запросов
- Типы данных бд
- Таблица
- Строка
Если мапперы способны повсеместно создаваться в коде, то неплохо бы иметь односложный конструктор, в этом случае все необходимое нужно засунуть только в один класс. С одной стороны, это рано или поздно приведет к совмещению обязанностей в одном классе, с другой стороны - упрощение сборки позволяет обойтись без всяких фабрик и т.п., которые тоже требуют своей сборки, а классы которые их собирают своей сборки и т.п. водопад зависимостей. Ради унификации назову его ConnectionManager, хотя это скорее ConnectionContext или что-то подобное, но не суть. Соединение связано с билдером специфических запросов и с менеджером специфических типов.
Предполагаю, что метод, приводящий объект к структуре ключ-значения реализован, например, в каком-нибудь ClassUtil.toMap, а также реализован метод получения полей java.lang.reflect.Field сущности. Я не рассматриваю их, все легко гуглится. Разве что нужно помнить о родительских полях, а появление модулей может потребовать дополнительную проверку для рефлексивного доступа через java.lang.Module#isOpen.
В самом простом случае можно подумать о простом билдере на основе списка, однако для сброса дублированного кода нужен еще один класс, также назову его менеджером. Стоит понимать, что эти классы тесно завязаны на SQLite и над ними будут более общие методы, а в названии, как правило, будет присутствовать специфическая бд.
Упрощенно:
//конечно же, подразумевается SqliteQueryBuilder
class SqlQueryBuilder {
private String wildcard
private String preparedPlaceholder
private List<String> queryParts = []
SqlQueryBuilder(String wildcard = "*", String preparedPlaceholder = "?") {
this.wildcard = wildcard
this.preparedPlaceholder = preparedPlaceholder
}
SqlQueryBuilder select() {
//можно добавить и как <<, я по старинке
queryParts.add("SELECT")
//можно избавиться от this, аннотируя как @Builder для Fluent interface
return this
}
//разные похожие методы
@Override
String toString() {
//есть смысл проверить результат, не пустой ли он
return queryParts.join(" ")
}
}
class SqlQueryManager {
SqlQueryBuilder createSqlBuilder() {
//удобнее заменить на делегирующий вызов, поместив, например, java.util.function.Supplier через конструктор.
return new SqlQueryBuilder()
}
String selectAllFromTable(String tableName) {
String query = createSqlBuilder().selectAll().from(tableName)
return query
}
String selectAllFromTableWhereColumnPrepared(String tableName, String columnName) {
String query = selectAllFromTable(tableName).where().column(columnName).equalPrepared()
return query
}
}
К сожалению, здесь уже начинаются первые грабли. Билдер строго специфичен, но класс-менеджер для сброса дублированного кода хотелось бы сделать менее специфичным, но т.к. билдер обладает состоянием, то для его более надежного сброса используется новый объект, что требует фабричного метода и что потребует создания каждый раз класса-менеджера под специфичную бд.
Если в билдере сделать метод сброса, то нет гарантий, что он будет вызван. Если сбрасывать после приведения в строку, то это неочевидное изменение состояния... кгм. Вариантом может быть делегирование и создание его в том месте, где происходит определение типа бд, разве что в этом случае сборка может потребовать дополнительный данных и если будет простой Supplier, то построение может усложниться. В каком-то коде я видел проверку поддерживаемого функционала в билдере запросов, намек на то, что создание билдеров для разных баз данных с их разбросом в диалектах и специфических особенностях задача непростая.
Я использовал метод create, хотя существует определенное противоречие между отражением в названии метода его внутренней логики и унификации. С одной стороны, жизненно важно передать как можно больше информации в методе о его работе, с другой стороны, скорее всего привычка будет искать метод getQueryBuilder, хотя бы он и фабричный. Тоже относится и к некоторым методам ниже. Удобство унификации методов на геттеры и сеттеры может потребовать изменений имен для более быстрого доступа к ним когда метод не содержит критичного побочного эффекта. Это достаточно опасно, если метод определяется интерфейсом или изменять его уже нельзя - если при создании билдера будет выбрасываться исключение, то очень неприятно напороться на него в геттере.
Кроме того, в практике встречается приём разграничения методов с префиксами навроде new и create: первый для чистого создания объекта без других побочных эффектов, который перопределяется потомком с целью подмены реализации, второй - фабричный, для более сложной сборки. Я использовал второй вариант как более гибкий, но, вероятно, может быть лучшей идеей сразу разделить сборку и создание объекта.
Менеджер типов также может быть очень простым:
//подразумевается SqliteTypeManager
class TypeManager {
int fromBoolean(Boolean value) {
//возможно, есть смысл избавиться от примитивов
int intValue = value ? 1 : 0
return intValue
}
//toBoolean и т.п.
}
Теоретически, без него можно и обойтись, но тогда могут быть очень сильные проблемы при запросе вручную, а это важное требование исходя из рисков маппинга с его непредсказуемостью. Для каждой бд типы разные и неоткуда это узнать.
Теперь можно собрать и менеджер, аналогом groovy.sql.Sql скорее будет java.sql.Connection:
class FileConnectionManager {
final File dbFile
final TypeManager typeManager
final SqlQueryManager sqlQueryManager
ConnectionManager(File dbFile, TypeManager typeManager, SqlQueryManager sqlQueryManager) {
//проверка файла и т.п.
this.dbFile = dbFile
this.typeManager = typeManager
this.sqlQueryManager = sqlQueryManager
}
protected Sql createJdbcConnection(String dbType, Properties config) throws SQLException {
String dbData = "jdbc:$dbType:${getDbFile().getAbsolutePath()}"
Sql sql = Sql.newInstance(dbData, config)
return sql
}
Sql createConnection(Properties properties = null) throws SQLException {
Properties connectionConfig = Objects.requireNonNullElseGet(properties, {
SQLiteConfig config = new SQLiteConfig()
config.enforceForeignKeys(true)
return config.toProperties()
})
Sql connection = createJdbcConnection("sqlite", connectionConfig)
return connection
}
}
Конечно, в иерархии абстракций выше будет класс ConnectionManager и т.д. вверх по иерархии. Напомню, что я использую легаси File из-за дефолтного импорта java.io.* в Groovy, а также по смыслу этого класса абстракция файла выглядит лучше, чем абстракция пути Path, хотя, конечно же, File можно и заменить, учитывая его недостатки.
Теперь можно создать класс, который будет служить местом сброса дублированного кода для работы со строкой бд. Однако строка существует в контексте таблицы, класс которой занимает ключевое значение во всей структуре маппера, в чем-то компенсируя отсутствие аннотаций:
abstract class UniqueTable {
final String idColumn
UniqueTable(String idColumn = "id") {
this.idColumn = idColumn
}
abstract String getTableName()
private List<String> filterNotIdTableColumns(List<String> columns) {
//если ключи сортированы, то можно пытаться обнаруживать только несколько первых совпадений.
return columns.findAll { it != getIdColumn() }
}
List<String> getTableColumnsWithoutId() {
List<String> withoutId = filterNotIdTableColumns(getTableColumns())
return withoutId
}
List<String> getShortTableColumnsWithoutId() {
List<String> withoutId = filterNotIdTableColumns(getShortTableColumns())
return withoutId
}
List<String> getTableColumns() {
String tableName = getTableName()
//как tablename.column
List<String> columnsWithTableName = getShortTableColumns().collect { tableName.concat(".").concat(it) }
return columnsWithTableName
}
List<String> getShortTableColumns() {
//рефлексивное получение полей и чтение их текстовых значений, здесь имеет смысл проверить тип
final List<String> columns = ClassUtil.toMap(this).collect { fieldNameAndValueEntry ->
String.valueOf(fieldNameAndValueEntry.getValue())
}
return columns
}
String getColumnsAsString() {
String columnsAsString = getTableColumns().join(",")
return columnsAsString
}
}
List можно даже абстрагировать до Collection. В этот же класс (или более специализированный подкласс) можно поместить различные подстраховки для исключения попадания опасных символов в имена столбцов и таблиц и предотвращения SQL-инъекции. В целях упрощения здесь сразу уникальная таблица, над ней должна быть "какая-то базовая таблица" и т.п. Вспомогательные методы необходимы для разных случаев запросов, например, в случае апдейта или вставки могут пригодиться имена столбцов без первичного ключа, иногда нужны имена столбцов и именем таблицы и без.
Есть определенные вопросы к получению имен столбцов, как видно, там запрятан рефлексивный метод, который может намекнуть на отделение этой логики в другой класс, вроде TableParser или что-то такое, кроме того, логика валидации или фильтра от SQL-инъекции тоже по идее не должна быть включена в класс самой таблицы. Выходит, что класс таблицы выше все же состоит из чистой сущности - таблицы с простыми геттерами и сеттерами и логики парсинга столбцов, по сути два класса в одном. Так что, возможно, его есть смысл разделить на два, а в коде использовать какой-нибудь TableManager\TableParser или что-то в этом роде, оставляя в классе таблицы лишь имена столбцов, не более. С другой стороны, это усложнит некоторые вызовы.
Здесь могут быть проблемы из-за специфичности бд: находясь в самом классе таблицы эти вспомогательные методы получения столбцов связываются с ней, определяя возможности всех таблиц в приложении. Если будет несколько бд с разными требованиями к именованию столбцов, то будет беда. В данном случае так проще, но это намекает на необходимость еще одного класса, который будет управлять таблицей. С другой стороны, проблему можно решить и без него.
Таблицы есть и можно описать менеджер строк:
abstract class TableRowManager<T extends UniqueTable> {
final ConnectionManager connectionManager
private final T table
protected abstract T createTable()
DbTableRowManager(ConnectionManager connectionManager) {
this.connectionManager = connectionManager
this.table = createTable()
//предохранитель от некорректной работы фабричного метода
assert this.table != null
}
T getTable() {
return table
}
//может быть удобным в запросах, когда имя таблицы часто требуется
String getTableName() {
return table.getTableName()
}
Map<String, Object> toImmutableMap(GroovyResultSet rowResultSet) {
//имеет более строгий котракт в сравнении с Map и выбрасывает NPE
GroovyRowResult rowResult = rowResultSet.toRowResult()
//не очень хорошее минирование кода иммутабельной коллекцией, но позволяет подстраховаться лишний раз от перезаписи ключей, каст для static type checking, возможно, это можено сделать и без каста.
Map<String, Object> rowMap = rowResult.asImmutable() as Map<String, Object>
return rowMap
}
}
Не самый удачный и часто порицаемый способ привести объект в корректное состояние, вызывая в конструкторе переопределяемый в потомках метод, но это снимает многие неудобства. Если запись ссылки в поле вынести в какой-либо метод, то это сразу же потребует управления состоянием, а установка таблицы клиентским кодом через сеттер здесь неудобна.
Изначально я пробовал создать отдельный класс, описывающих строку, но его использование оказалось не очень удобным. Для чего в простом случае нужна работа со строкой... например, библиотека пагинации может потребовать большого количества объектов, маппинг которых сразу же убьет приложение. При отсутствии таких требований, наверное, от этого класса для работы со строками можно даже избавиться или выделить его позже, когда появится дублирование кода, но нужно будет перемещать метод преобразования строки таблицы в мапу.
Здесь есть тонкий нюанс в фабричном методе, посредством которого менеджер должен предоставлять специфическую таблицу. Делегирование, как в случае с билдером запросов здесь уже не особо поможет. С одной стороны, метод можно заменить на конструктор DbTableRowManager(T table, ConnectionManager connectionManager), с другой стороны, т.к. конструктор должен всегда вызываться первым, то сложная сборка таблицы может стать очень проблематичной. Отмечу, что менеджер соединений находится в public поле ради возможности получения соединения от маппера в сложных случаях, закрывать его или нет - вопрос достаточно противоречивый.
Классы выше позволяют выполнять запросы вручную, практически игнорируя маппинг и предназначены для сложных случаев.
Центральное место в самом маппинге будет занимать класс-преобразователь. Но его нельзя назвать конвертером или трансформером за счет наличия связанных операций вставки и обновления для некоторых отношений, название не будет отражать побочный эффект. Где-то мне встречался подобный класс и назывался как Receiver, назвать можно совершенно по-разному.
Снова вспомним отображение f:A→B. Из его определения можно выудить основные элементы: поле сущности, значение бд и правило отображения, которое используется по условию. Попробуем определить условие только лишь для поля сущности, используя функциональный интерфейс java.util.function.Predicate, тогда класс убер-солдат, который должен справляться с большей частью случаев может выглядеть как-то так:
abstract class EntityFieldDbValueMapping<FieldValue, DbValue> implements Predicate<Field> {
//возможно, isRemapped более лучший вариант
final boolean remapped
EntityFieldDbValueMapping(boolean isRemapped) {
this.remapped = isRemapped
}
Map<String, DbValue> toDatabaseMapFromField(String fieldName, FieldValue fieldValue, Sql connection) throws SQLException {
Map<String, DbValue> mapForDb = [:]
Optional<DbValue> mustBeValue = toDatabaseFromField(fieldName, fieldValue, connection)
//может быть проблема в случае записи null в бд, тогда поле не отобразится на бд вообще
//mustBeValue.ifPresent { newValue -> mapForDb.put(fieldName, newValue) }
//или всегда помещать ключ в отображение, но тогда контракт возвращаемой мапы несколько запутывается и можно забыть переопределить метод, например, для один-ко-многим будет ошибка.
//mapForDb.put(fieldName, mustBeValue.orElse(null));
//более удобный вариант - if(remapped) по первому варианту, а если нет, то по второму.
if(remapped){
mustBeValue.ifPresent { newValue -> mapForDb.put(fieldName, newValue) }
}else {
mapForDb.put(fieldName, mustBeValue.orElse(null));
}
return mapForDb
}
Optional<FieldValue> toFieldFromDatabaseMap(String fieldName, DbValue databaseValue, Sql connection, Map<String, Object> databaseRowValues) throws SQLException {
return toFieldFromDatabase(fieldName, databaseValue, connection, databaseRowValues)
}
abstract protected Optional<DbValue> toDatabaseFromField(String fieldName, FieldValue fieldValue, Sql connection) throws SQLException
abstract protected Optional<FieldValue> toFieldFromDatabase(String fieldName, DbValue databaseValue, Sql connection, Map<String, Object> databaseRowValues) throws SQLException
//можно попробовать назвать как before* и т.п. В некоторый руководствах вообще не рекомендуется использовать такие префиксы, но отдать им должное - они универсальны
void preInsertFieldValue(String fieldName, FieldValue fieldValue, Sql connection) throws SQLException {
}
//в зависимости от реализации вставки и обновления, сигнатура может отличаться: например, данные об имени поля могут быть уже недоступны на момент вызова пост-методов
void postInsertFieldValue(String fieldName, FieldValue fieldValue, Sql connection) throws SQLException {
}
void preUpdateFieldValue(String fieldName, FieldValue fieldValue, Sql connection) throws SQLException {
}
void postUpdateFieldValue(String fieldName, FieldValue fieldValue, Sql connection) throws SQLException {
}
}
Я выбрал только лишь поле сущности из-за потенциального наличия в ней полиморфной связи, тогда кол-во полей больше столбцов. Можно попытаться использовать и поля, и столбцы, и массу других данных для условия, хотя это и сложнее, даже использовать что-то вроде спецификации.
Здесь есть также вопросы относительно полноты данных, передаваемых маппингу. Например, может потребоваться сам объект сущности, возможно, даже не собранный. Я достаточно долго экспериментировал с именами класса и его методов: сделать их более короткими, но менее информативными - чрезвычайно плохая идея. Название самого класса выглядит длинноватым, но для быстрого вспоминания в нем есть смысл отразить расположение параметризации - на первом месте тип поля, на втором - тип бд, что соотносится с именем. Тоже самое относится и к методам: пробовал toDatabase\fromDatabase и т.п. варианты. Несколько раз пройдясь по граблям их неправильного использования решил сделать их длиннее, но более информативными с заложенными мнемониками в именах.
Такой класс маппинга можно построить разными способами, например, избавиться от методов вставки\обновления. Я разделил их, предполагая сильный побочный эффект и вылетевшее исключение, которое проще отделить от логики отображения, ну и чем-то это напоминает CQRS с отделением побочного эффекта. С другой стороны, их наличие может показаться излишним, а название уводить в сторону. Действительно, может возникнуть резонный вопрос: preUnsert какой сущности подразумевается - той, которая в fieldValue или той, за которую отвечает совсем другой маппер, что сбивает с толку.
Значение поля Integer databaseValue уже входит в мапу databaseRowValues и если обернуть её в более строгую структуру, что можно сильно сократить сигнатуру. С другой стороны, менеджер сущности может дополнительно сделать какие-то проверки, да и параметризация усложняется... Обращение к сырым данным - это серьезные риски и мапа передается скорее для нестандартных случаев, вроде внедренного объекта.
Рассмотрим несколько частных случаев:
- В случае простого маппинга в Groovy-тип и обратно реализуются только абстрактные методы и remapped = false. Можно проверить имена полей и имена столбцов на полное соответствие.
- Для один-к-одному реализуются абстрактные методы, remapped = false, используется preInsertFieldValue и preUpdateFieldValue для транзакционных операций вставки и обновления в случае необходимости. Также можно проверить на полное соответствие.
- Для один-ко-многим remapped = true: в таблице из бд нет столбца, который указывает на таблицу со многими, нельзя проверить поля сущности и столбцы - в сущности будет лишние поле. В toFieldFromDatabase может быть null. Также toDatabaseFromField ничего не возвращает и маппер отдает пустую мапу, вставка и обновление через pre* или post*-методы в зависимости от структуры внешних ключей. Так, если в таблице "многих" внешний ключ указывает на таблицу "одного", то нужно сначала вставить "одного", а только затем вставлять "многих". Проблема с обратной ссылкой, можно попытаться проставлять их после сборки, введя досборочные и послесборочные методы, например, postCreate или что-то в этом роде.
- Embedded объект - remapped = true, нельзя проверить на соответствие: в поле сущности будет лишние поле внедренного объекта, а в таблице столбцы, из которых он собирается и которых не будет в сущности. Здесь нужно переопределение toDatabaseMapFromField, чтобы разобрать внедренный объект на поле в мапу и вставить в бд значения его полей. В случае же его сборки в методе toFieldFromDatabase может быть null, а нужно использовать мапку со всеми значениями Map<String, Object> databaseRowValues.
Однако при такой архитектуре есть одна проблемка: если изначально в бд было, например, текстовое значение, а потом его полностью удалили, то конвертер может вернуть null и мапа не будет сформирована. Для бд, которая следует советам освобождения от null это меньшая проблема, а вот для другой, возможно, есть смысл освободиться от Optional, заставляя переопределять больше методов, но не имея подобных багов с null и некорректной работой ifPresent\isEmpty. Еще здесь может быть удобным флаг ремаппинга - если он выставлен, то проверять значение в Optional, а если нет, то всегда отображать поле на бд, получая возможность записывать туда null.
Таким образом, класс не является NVI интерфейсом, хотя изначально чем-то на него похож. К сожалению, разные случаи маппинга требуют переопределения самых разных методов. Здесь в глаза бросается совмещение ответственностей - класс одновременно и отображает и делает запросы к бд, обращаясь к мапперам. С другой стороны, маппинги строго специфичны для каждой таблицы и создание их может занимать все основные время, поэтому расслоение скорее будет внутреннее, без раскрытия данных... кгм.
Опишем базовую сущность. Наследование от неё завязывает логику на пакет данных, но в ином случае идентификаторы будут дублированием кода, а любое дублирование опасно изменениями. Можно использовать параметризацию для id, но это добавит проблем.
import javax.validation.constraints.NotNull
class UniqueEntity {
@NotNull
//типа Integer может и не хватить
Integer id
void setId(Integer id) {
assert id != null && id >= 0
this.id = id
}
}
Несложно предсказать, что если этот класс будет находиться в пакете базы данных, то все сущности будут привязаны к работе с бд, что при последующей смене источника данных потребует рефакторинга. Тип Integer здесь я использовал больше для синхронизации с драйвером sqlite, чтобы не делать лишний раз касты в более объемный Long: за счет динамической природы SQLite при дефолтной схеме бд его максимально 8-байтный INTEGER мапится на джавовский Integer и если из бд в сущность такой каст может быть безопасен как Integer -> Long, то обратно будет выходить Long -> в Integer, что уже неприятно.
Связь один к одному через первичный ключ теперь может выглядеть как-то так:
abstract class ByNameFieldDbValueMapping<EntityValue, DbValue> extends EntityFieldDbValueMapping<EntityValue, DbValue> {
private final String fieldName
ByNameFieldDbValueMapping(String fieldName, boolean isRemapped) {
super(isRemapped)
this.fieldName = fieldName;
}
@Override
boolean test(Field field) {
//в Groovy работает как equals
return field.getName() == fieldName
}
}
class OneToOneFieldDbValueMapping<E extends UniqueEntity, T extends UniqueTable> extends ByNameFieldDbValueMapping<E, Integer> {
private final TableEntityManager<E, T> foreignEntityManager
OneToOneFieldDbValueMapping(TableEntityManager<E, T> foreignEntityManager, String foreignTableColumn) {
//remapped в false, но это уменьшает гибкость, возможно, лучше передать через конструктор с дефолтным значением false, но это может и нарушить логику отображения, кгм
super(foreignTableColumn, false)
this.foreignEntityManager = foreignEntityManager
}
//@Override
void preInsertFieldValue(String fieldName, E fieldValue, Sql connection) throws SQLException {
if(fieldValue == null){
//скорее всего лучше вернуть булево значение или число затронутых сущностей, а не void, чтобы клиентский код мог знать результат, но для этого нужно также проверять и результаты insert\update
return;
}
//простая проверка, может быть ситуация гонки
Optional<E> mustBeExistingForeign = foreignEntityManager.findById(fieldValue.getId(), connection)
if (mustBeExistingForeign.isEmpty()) {
foreignEntityManager.insert(fieldValue, connection)
}else {
//частный случай
foreignEntityManager.update(fieldValue, connection)
//или же assert mustBeExistingForeign.isEmpty()
}
}
//@Override
void preUpdateFieldValue(String fieldName, E fieldValue, Sql connection) throws SQLException {
if(fieldValue == null){
//тоже самое, результат обновления трудно узнать
return;
}
Optional<E> mustBeExistingForeign = foreignEntityManager.findById(fieldValue.getId(), connection)
//дублирование логики выше, переверну проверку, чтобы первой шла операция, связанная с именем метода
if (mustBeExistingForeign.isPresent()) {
foreignEntityManager.update(fieldValue, connection)
}else {
//частный случай
foreignEntityManager.insert(fieldValue, connection)
//или же assert mustBeExistingForeign.isPresent()
}
}
//@Override
protected Optional<Integer> toDatabaseFromField(String fieldName, E entity, Sql connection) throws SQLException {
if (entity == null) {
return Optional.empty()
}
return Optional.of(entity.getId())
}
@Override
protected Optional<E> toFieldFromDatabase(String fieldName, Integer databaseValue, Sql connection, Map<String, Object> databaseRowValues) throws SQLException {
if (databaseValue == null) {
return Optional.empty()
}
Optional<E> mustBeForeignEntity = foreignEntityManager.findById(databaseValue, connection)
return mustBeForeignEntity
}
}
Класс достаточно наивен и не имеет никаких флагов для управления вставкой или обновлением, создавая опасные ситуации обновить всю бд сразу, но их запросто можно добавить. Возникает разве вопрос, кто должен делать проверку этих флагов: если это сделает сторонний код, то флаги можно добавить в сам EntityFieldDbValueMapping, но за счет иммутабельности потребуется проброс этих флагов через все конструкторы. Так как связанные операции используются лишь в части случаев, то это может быть обременительным, хотя и гарантирует более строгую логику: сам класс может проверить флаг, а может и не проверить. Проще все же выделить управляемый класс, от которого наследуются маппинги один-к-одному, один-ко-многим и т.п.
Особый интерес представляют несколько частных случаев, в зависимости от наличия или отсутствия в бд связанных сущностей. При этом в методе вставки может выполняться обновление, а в методе обновления вставка. Такая ситуация может быть, например, когда в одном и том же интерфейсе происходит управление несколькими типами сущностей. Тогда создание сущности вставляет её в бд как рутовую, а последующая правка трансформирует её в связанную сущность для один-к-одному, а т.к. в бд она уже есть, то при вставке должно произойти обновление тех же флагов, которые могут указывать признак связанности или чего-то подобного. Если же сильно захотеть предварительно удалить существующую, то за счет каскадного поддержания целостности внешних ключей могут быть неприятности. Причем поведение сходно и для вставки и для обновления, эту общую логику можно вынести, хотя тут есть парочка проблем: имя методов не отражают побочных эффектов и в случае наличия двух раздельных булевых флагов для управления поведением можно получить неожиданное поведение. Например, есть флаги: нужно ли вставлять и обновлять связанную сущность, тогда может быть проблема с проверкой этих флагов, ибо это может происходить как при вставке, так и при обновлении. Если проверки флагов будут ориентироваться на операции, то при выключении одного флага можно получить немного неожиданное поведение за счет наличия обоих флагов в методах вставки и обновления одновременно.
С другой стороны, такая ситуация может говорить и о нарушениях логики в программе, поэтому я все же пометил его комментарием как частный случай. Возможно, там должна стоять проверка assert и бросаться исключение, как в случае невалидного состояния данных в бд или можно вообще ничего не делать, доверившись ограничениям в самой бд. Как вариант - ввести более специализированный подкласс, который рассматривает связь один-к-одному более строго, проверяя, что при вставке - обоих сущностей (основная и связанная) нет в бд, а при обновлении они обе присутствуют, либо по обстоятельствам.
Есть здесь и еще досадный недостаток - параметризация. Во-первых, раскрывается информация о типе идентификатора, но самое неприятное - дженерики для вложенного менеджера сущности, которые раскрывают тип сущности и таблицы для вложенного менеджера. С другой стороны, компилятор может автоматически вывести типы, но все же об этих данных классу, который должен создавать связь совершенно необязательно знать. Можно еще попробовать затереть тип, но дженерики инвариантны и скорее всего даже в Groovy статическая проверка типов провалится и нужно будет бодаться с кастами.
Закомментированные аннотации - это проблема в режиме static type checking, чем-то похожая на GROOVY-6654. IDE говорит, что поля переопределены, но Groovy с этим не согласен.
Рассмотрим преобразование типа бд в Groovy тип. Кроме сложности с определением типов в бд здесь таится еще одна проблема - преобразования специфичны и зависят от бд. Так, в SQLite булев тим может быть сохранен как INTEGER, поэтому Integer в Boolean и Boolean в Integer будут зависеть только от бд. Это означает, что эти конвертеры\маппинги как-то нужно передавать извне.
В самом простом случае на ум приходит простой контекст или что-то такое:
//подразумевается, конечно же, SQLiteMappingContext
final ConnectionManager connectionManager
final List<EntityFieldDbValueMapping<?, ?>> fieldDbValueMappings = []
MappingContext(ConnectionManager connectionManager, List<EntityFieldDbValueMapping<?, ?>> fieldDbValueMappings = []) {
this.connectionManager = connectionManager
if (!fieldDbValueMappings.isEmpty()) {
this.fieldDbValueMappings.addAll(fieldDbValueMappings)
}
//false выставляет remapped в false, такой конвертер будет наследоваться от конвертера, который делает это сам, а также проверяет поле и т.п., оставил только для наглядности
this.fieldDbValueMappings << new EntityFieldDbValueMapping<Boolean, Integer>(false) {
@Override
Optional<Integer> toDatabaseFromField(String fieldName, Boolean fieldValue, Sql sql) throws SQLException {
//assert fieldValue != null
return Optional.of(connectionManager.getTypeManager().fromBoolean(fieldValue))
}
@Override
Optional<Boolean> toFieldFromDatabase(String fieldName, Integer databaseValue, Sql sql, Map<String, Object> valuesFromDb) throws SQLException {
//assert fieldValue != null
//нехороший упрощенный каст в int, но который может закончиться неприятностями, связанными не только с перепаковкой
return Optional.of(connectionManager.getTypeManager().toBoolean((int) databaseValue))
}
@Override
boolean test(Field field) {
return field.getType() == Boolean.class
}
}
}
}
Использование Optional.of вместо ofNullable не предполагает наличие null, но здесь могут быть разные варианты. Если валидатор выявит null, то это может говорить о неправильном маппинге, когда как получение null из бд и превращение его в булев тип может замаскировать эту проблему, если менеджер типов профукает этот случай и обработает null-значение как false. С другой стороны, валидатор также может не быть или он сработает неверно, а в бд null может и предполагаться как false. Замена на что-то более строгое, например аналог Optional проблему особо не решает - менеджер типов как хочет, так и обработает. Вывод: дополнительные проверки в маппингах могут очень сильно помочь, но на всякий случай я закомментировал их,
Менеджер соединений отделен от маппинга, что вполне логично. Но возможна проблема, если этот менеджер создается на основе данных о бд - файле, например. Тогда менеджер бд определяет, что прилетел файл и делает new SQLiteConnectionManager. Этот менеджер ничего не знает о маппинге, который также специфичен для соединения. За счет того, что конструкторы мапперов односложны туда можно передать либо маппинговый контекст либо универсальный менеджер соединений, что требует определенного усложнения или переделки готового и работающего кода. Вполне может получиться замкнутый круг и конвертеры\мапперы уедут в сам менеджер соединений, костыльно завязав таким образом пакет на маппинг. Такая вот жертва...
Осталось вспомнить, что валидация сущностей может подстраховать от разных неприятных событий. Создадим простейший валидатор, я буду использовать апи от Jacarta:
// @Grab(group = 'jakarta.validation', module = 'jakarta.validation-api', version = '2.0.2')
import javax.validation.constraints.NotNull
class SimpleEntityValidator<E extends UniqueEntity> {
void validate(E entity) {
//каким-то образом получаем поля и фильтруем их для аннотации
List<Field> notNullFields = ClassUtil.getAccessibleFields(entity).findAll { field ->
field.getAnnotation(NotNull.class)
}
notNullFields.each { field ->
final String fieldName = field.getName()
//Groovy-метод GroovyObject#getProperty
Object value = entity.getProperty(fieldName)
if (value == null) {
throw new RuntimeException("Validation failure: field '$fieldName' in ${entity.getClass().getName()} must not be null")
}
}
}
}
Разумеется, валидатор должен иметь более сложное устройство, интерфейс, иметь состояние и т.п.
Осталось определить менеджер сущностей, на основе всех классов выше.
abstract class TableEntityManager<E extends UniqueEntity, T extends UniqueTable> extends TableRowManager<T> {
//типы затираются
final List<EntityFieldDbValueMapping<?, ?>> fieldDbValueMappings = []
//сохраняется инфа о классе для операций выборки и т.п.
final Class<E> entityClass
private SimpleEntityValidator<E> entityValidation
TableEntityManager(Class<E> entityClass, MappingContext mappingContext, SimpleEntityValidator<E> entityValidation = new SimpleEntityValidator<>()) {
super(mappingContext.getConnectionManager())
this.entityClass = entityClass
this.entityValidation = entityValidation
//объединяются для упрощения, но могут быть раздельными
fieldDbValueMappings.addAll(mappingContext.getFieldDbValueMappings())
}
Optional<E> tryToCreateFromMap(Map<String, Object> valuesFromDb, Sql sql, boolean validate = true) {
//проверка, пуста ли мапа, об этом ниже
//assert !valuesFromDb.isEmpty()
if(valuesFromDb.isEmpty()){
//залогировать?
return Optional.empty()
}
//каст as E для проверки типов
E entity = getEntityClass().getDeclaredConstructor().newInstance() as E
//каким-то образом получаются поля
final List<Field> entityFields = ClassUtil.getAccessibleFields(entity)
assert !entityFields.isEmpty()
//самая наивная проверка на однозначность, is - синтетический геттер, хотя можно сразу назвать isRemapped.
final boolean isRemapped = fieldDbValueMappings.any { it.isRemapped() }
if (!isRemapped) {
final List<String> entityFieldsNames = entityFields*.name
final List<String> dbColumnsNames = valuesFromDb*.key
final List<String> difference = entityFieldsNames + dbColumnsNames - entityFieldsNames.intersect(dbColumnsNames)
//тут assert недостаточен, нужна информация о сущности и т.п.
assert difference.isEmpty()
}
entityFields.each {
field ->
final String fieldName = field.getName()
//если маппинг неоднозначен, то ключа не будет в именах столбцов и может выскочить NPE, можно сделать по условию isRemapped
Object valueFromDb = valuesFromDb.getOrDefault(fieldName, null)
fieldDbValueMappings.each { mapping ->
if (mapping.test(field)) {
//здесь будут выскакивать исключения, т.к. в груви они непроверяемые, то это никак не помечается
Optional<?> mustBeNewValue = mapping.toFieldFromDatabaseMap(fieldName, valueFromDb, sql, valuesFromDb)
mustBeNewValue.ifPresent { newValue ->
valueFromDb = newValue
//здесь можно проверить сразу, чтобы исключить ошибку маппинга, если не null, то assert field.getType() == valueFromDb.getClass()
}
}
}
if (valueFromDb != null) {
//наивно, тип может расширяться, например, int в long
assert field.getType() == valueFromDb.getClass()
}
//опасный вызов GroovyObject#setProperty
entity.setProperty(fieldName, valueFromDb)
}
//флаг нужен для отключения валидации, например, когда потомок хочет "дособрать" сущность сам, перекладывая валидацию на себя
if (validate) {
entityValidation.validate(entity)
}
return Optional.of(entity)
}
//какой-нить вспомогательный метод
protected List<E> toList(Sql sql, String query, List<Object> params = []) {
List<E> entities = []
sql.eachRow(query, params) { resultSet ->
//наверное, такой постоянный перегон в мапу для списка может вызвать какие-то накладные расходы
Optional<E> mustBeEntity = tryToCreateFromMap(toImmutableMap(resultSet), sql)
mustBeEntity.ifPresent {
entities << mustBeEntity.get()
}
}
return entities
}
//нетранзакционный для выборки, хотя можно сделать флаг для транзакций или вообще сделать его транзакционным
List<E> findAll() throws SQLException {
try (Sql sql = connectionManager.createConnection()) {
List<E> entities = findAll(sql)
return entities
}
}
List<E> findAll(Sql sql) throws SQLException {
String query = connectionManager.getSqlQueryManager().selectAllFromTable(getTableName())
List<E> entities = toList(sql, query)
return entities
}
//разные другие методы
}
Простая проверка на взаимооднозначность наивна, но позволяет исключить потенциально ненужные запросы из вложенных мапперов. Попробуем взвесить риски, что будет в случае расхождения множеств. Рассмотрим Поля и Столбцы:
- Если Поля сущности пусты, но класс невалиден, нельзя отобразить пустой класс во что-то, ведь класс создан для описания отображения какой-то таблицы.
- Если Столбцы пусты, то сущность может отсутствовать в бд, с другой стороны, это может быть ошибкой. Если пойти по первому варианту, то это снимает ответственность за проверку результата с кода в запросах. Если пойти по второму, то можно предотвратить коварные ошибки, но получить случайный рантаймовый эксепшен.
- Очевидно, что Поля и Столбцы одновременно пустыми быть не могут.
- Поля == Столбцы интереса не представляет, но конвертер может попытаться превратить null в значение, например в строку ''. Если драйвер позволяет соотнести типы бд и типы Groovy, то можно было бы проверить возвращаемое значение.
- Полей больше Столбцов, например, один-ко-многим, где на поле сущности будет список из совершенно другой таблицы. Также все маппинги будут тестироваться. Проверить можно разве что созданием определенных классов маппингов, которые несут информацию о результате маппинга.
- Полей меньше Столбцов, например, embedded object. Также нужно хитро отслеживать результат.
Итого, несколько случаев требуют сильной зависимости кода от типа маппингов и учета результатов их работы для гарантий корректности преобразования. Появляется зависимость между гибкостью маппинга и его строгостью.
Отсутствие проверки в метод entity.setProperty(fieldName, valueFromDb) само по себе достаточно опасно, однако приходящая на ум проверка тождества классов при получении значения из маппера и класса поля assert field.getType() == valueFromDb.getClass() не покрывает случай, когда, например идентификатор в бд хранится как Long, но возвращается как Integer, а поле сущности Long с учетом расширения на будущее. С другой стороны:
class TestClass {
Integer foo
}
TestClass testClass = new TestClass()
testClass.setProperty("foo", Long.MAX_VALUE)
println testClass.foo
//-1
Без каких-либо проверок в условиях GroovyObject#setProperty скорее всего можно очень пострадать.
Метод выборки слишком прост, но метод обновления может быть транзакционным или иметь флаги для создания транзакций, если у маппера нет в них нужды
void insert(E entity) throws SQLException {
//не допускаем вставки некорректного объекта
entityValidation.validate(entity)
try (Sql sql = connectionManager.createConnection()) {
//исключение в замыкании приводит к откатыванию транзакции, но только в пределах "своего" соединения
sql.withTransaction {
insert(entity, sql)
}
}
}
Он может сразу проверять, количество обновившихся строк, предполагая, что проверку наличия сущности в бд должен сделать вызывающий. Или возвращать сущность. тогда будет как < S extends E > insert(S entity) для возврата корректного типа.
Вставка выше приводит к мысли о добавлении к связям-маппингам (EntityFieldDbValueMapping) информации о наличии подзапросов и необходимости транзакции. Тогда в случае их отсутствия транзакции можно не создавать, однако это сделает управление маппингом сложнее - следить нужно уже за несколькими флагами и за счет иммутабельности их пробрасывать, да и всегда есть шанс что-то напутать. К сожалению, из-за многопрофильности класса маппинга этой управляющей информации будет становиться все больше и больше.
Вставка и обновление будут зависеть от метода преобразования сущности в Map. Там также опрашиваются маппинги, проверка на однозначность и т.п. по аналогии. Единственное, нужно вызвать методы preInsert\Update, как и их post-аналоги,
Конечно же, возиться с описанием таблиц и классов такая себе идея, можно быстренько сделать наколеночный генератор, который создает каркас трех классов:
- Класс таблицы хорошо генерируется на основе метаданных соединения, разве что может быть проблема приведение множественного числа имени таблицы в единственное число класса таблицы
- Класс менеджера можно быстро создать без описания связей, а вот дальше уже зависит от драйвера
- Класс сущности, в котором узнать тип поля также может сложной задачей. Кроме того, генератор ничего особо не знает о возможной иерархии сущностей, например в бд много одинаковых полей - name, nameRu и т.п.
Генерация добавляет целый класс проблем - конфликты между полями родителя и Object\GroovyObject, ошибки из-за рефакторинга или изменений кода и т.п. В самом простом случае описание маппера строится на нескольких классах, поэтому генератор может быть также очень простым или тесно связанным с кодом. Например, для сущности, без учета типа внешних ключей может получиться что-то такое:
String generate(String packageName, String entityClassName, Map<String, Class<?>> tableColumns) {
//конечно же наследование может иметь глубокие иерархии и здесь они не учитываются
List<String> entityFieldsNames = UniqueEntity.class.getDeclaredFields()*.name
String entityFields = tableColumns.findAll { it.key !in entityFieldsNames }.collect {
return """
@${NotNull.simpleName}
${it.value.simpleName} ${it.key}
"""
}.join("")
String entityPattern = """package $packageName
//здесь все можно поместить в список импортов, избавляясь от дублирования
import ${UniqueEntity.class.name}
import ${ToString.class.name}
import ${NotNull.class.name}
/**
* @author
*/
//тут тоже можно что-то придумать, чтобы защититься от будущих изменений, который дадут рассинхронизацию
@${ToString.simpleName}(includeSuper = true)
class $entityClassName extends ${UniqueEntity.simpleName} {
$entityFields
}
"""
return entityPattern
}
}
Получается каркас:
class Sign extends UniqueEntity {
@NotNull
String name
//разные поля
@NotNull
AstroElement astroElement
}
Главное во всем этом - сгенерировать хотя бы имена полей и каркасы классов, которые копировать достаточно муторно. Из-за наивности генератора кое-где нужно доработать руками:
//учитывая схему бд для избавления от дублирования может быть сущность с полями name, nameRu и т.п.
class SignTable extends UniqueTable {
final String nameColumn = "name"
//столбцы таблицы
final String astroElementColumn = "astroElement"
String getTableName() {
return "signs"
}
}
class SignManager extends TableEntityManager<Sign, SignTable> {
private SignRulerManager signRulerDbManager
private SignModeManager signModeDbManager
private AstroElementManager astroElementDbManager
SignManager(SignRulerManager signRulerDbManager, SignModeManager signModeDbManager, AstroElementManager astroElementDbManager, MappingContext mappingContext) {
//параметризация очень грубая и не учитывает наследования, так что проброс класса через конструктор самого менеджера выглядит как-то бессмысленно.
super(Sign.class, mappingContext)
this.signRulerDbManager = signRulerDbManager
this.signModeDbManager = signModeDbManager
this.astroElementDbManager = astroElementDbManager
//тут тоже можно что-то придумать, очень легко получить ошибку, перепутав столбцы, но соответствие сущностей и таблиц может вызвать трудности
fieldDbValueMappings << new OneToOneFieldDbValueMapping<>(signRulerDbManager, getTable().signRulerColumn)
fieldDbValueMappings << new OneToOneFieldDbValueMapping<>(signModeDbManager, getTable().signModeColumn)
fieldDbValueMappings << new OneToOneFieldDbValueMapping<>(astroElementDbManager, getTable().astroElementColumn)
}
@Override
SignTable createTable() {
return new SignTable()
}
}
В глаза бросается некоторое различие между маппингом один к одному и связью один-к-одному, поскольку тот же элемент знака управляет сразу несколькими знаками, так что, возможно, такое название для классов выбрано не слишком удачно. Есть определенная проблема от смешивания реляционных понятий и объектных. Например, по логике вещей в относительно простом классе астроэлемента вполне может быть список знаков, но это порождает дополнительную зависимость элемента от знака и насколько там такой список полезен - это хороший вопрос: элемент сам по себе вполне можно рассматривать отдельно от знака, не вспоминая о последнем вообще. Если элемент управляет не только знаками, то таких зависимостей будет огромное количество, а для упрощения и производительности вполне можно делать отдельный запрос по необходимости.
Остается вопрос о более удобном управлении связанным обновлением или вставкой, скорее можно выделить специальные классы, например, какой-нибудь UpdateableOneToOneMapping, несколько сократив его имя, а то оно получится слишком уж длинным. Как видим, сборка менеджера знака достаточно сложна, да и имена столбцов легко перепутать. С другой стороны, создание маппингов можно упростить, использовав, например, аннотации, хотя я не особый их сторонник. Для такого простого случая связей в бд не особо много, так что простота устройства и удобство отладки может быть выше автоматизации.
Небольшие выводы:
Структура базы данных очень сильно влияет на маппинг. В случае создания бд для объектно-ориентированного отображения код определяет бд, иначе добиться упрощения проблематично. Чем больше расхождений - тем хуже. В принципе, это интуитивно - тем более разнородны множества, тем правила отображения запутаннее. Один из способ - уменьшить их различие, насколько это возможно.
Отображения значений просты, отображение связей проблемны из-за множества факторов, в т.ч. ограничений бд и производительности. Должен существовать единый принцип, по которому отображается наследование, ассоциация и т.п. отношения, пока я не встречал такого, он тесно связан с UML и отношениями классов, да и должен учитывать объектную модель в самом языке. Рано или поздно наложение факторов друг на друга приведет в неразрешимым противоречиям, нужно чем-то жертвовать - либо производительностью, либо архитектурой, либо тем и другим.
Большая проблема - целостность данных и ограничения внешних ключей. Для разных случаев меняется очередность вставки и обновления связанных сущностей, что требует разного набора различных методов.
Если использовать минимальное отображение наследования, например, в таблицах только для id-столбца, как и для сущностей, если развитый полиморфизм не требуется, то данных мапперу может быть достаточно для простых операций, а кодогенерация станет очень легкой. Для такого простенького приложения это может быть выгодным вариантом.
Даже такой простой велосипед вполне работоспособен, а в сочетании с кодогенерацией может сэкономить время. С другой стороны, в случае тонких багов времени также можно потерять очень много из-за недостатков велосипедостроения или получить невалидные объекты. Хотя и в случае сложных ORM времени также будет потеряно немало из-за неочевидного апи, неправильного его применения или при изменениях в них.С другой стороны, в суровых реалиях, где количество опенсурсных библиотек мало, а те, что существуют не подходят для проекта - выбора просто не будет.
Складывается впечатление, что использовать отображение в реляционных базах данных вообще затея плохая сама по себе, скорее всего так оно и есть, учитывая еще и сильное расхождение бд с потребностями современных языков программирования. Огромное количество нюансов, которые сильно запутывают код и делают его насыщенным багами и неочевидным поведением. Кроме того, в реляционной теории существует множество понятий, например, составные ключи и т.п., способные очень сильно осложнить маппинг или сделать его невозможным. Можно наступить на грабли автоинкремента первичного ключа, различии числового типа в драйвере и языке программирования и т.п., что делает задачу еще более нетривиальной. Хотелось бы видеть в современных языках большое количество orm-либ на разные случаи, как и наличие такого функционала в стандартной библиотеке, чтобы не зависеть от непредсказуемости стороннего разработчика. А пока остается лишь мечтать и страдать, наступая на многочисленные грабли своих велосипедов.
В примерах выше не раскрываются многие темы: кеширование объектов, наследование сущностей друг от друга, мапперов и отображение наследования на бд и т.п., которые вносят, конечно же, свои недостатки и проблемы, решение которых выходит за рамки простого эксперимента. В любом случае, эксперимент мне понравился, также порадовала возможность прикрутить к скриптовому языку полноценный десктопный тулкит, хотя бы и с потерями в производительности.