Захотелось немного архитектурно пошалить и поэкспериментировать с простеньким DSL (Domain-specific language) на русском.
Насчет русского языка в программировании ходят разные противоречивые мнения, но именно для предметных языков полезность смещается в сторону нативного, поскольку во многих областях устоялись строгие и определенные термины, перевод которых будет создавать множество самых разных проблем.
Меня интересует работа с данными и офисными документами, а здесь одного лишь синтаксиса недостаточно, в языке должны присутствовать сложные библиотеки для работы со всем этим.
Конечно же, на ум сразу приходит хорошая адаптация Groovy для создания DSL-инструментов и конфигураций, что дает неплохой архитектурный опыт, позволяя за счет различных механизмов делегирования и метапрограммирования немного иначе взглянуть на классические принципы объектной парадигмы и паттерны в ней.
Для работы с офисом можно использовать разные Java-библиотеки: Apache POI, OpenPDF, Apache PDFBox. Очень полезен проект tablesaw для работы с табличными данными, что может сильно упростить загрузку и разбор таблиц в .csv (есть еще и Commons CSV) и т.п. Такое большое количество качественных библиотек сильно облегчает работу и без них идея выглядит очень сомнительной - написать подобный библиотечный функционал крайне трудозатратно. Собственно, это еще одна причина выбора Groovy.
Простенький редактор для DSL-языка был построен тоже на Groovy с Swing и FlatLaf, для RSyntaxTextArea ограничился лишь автодополнением имен методов из разделов:
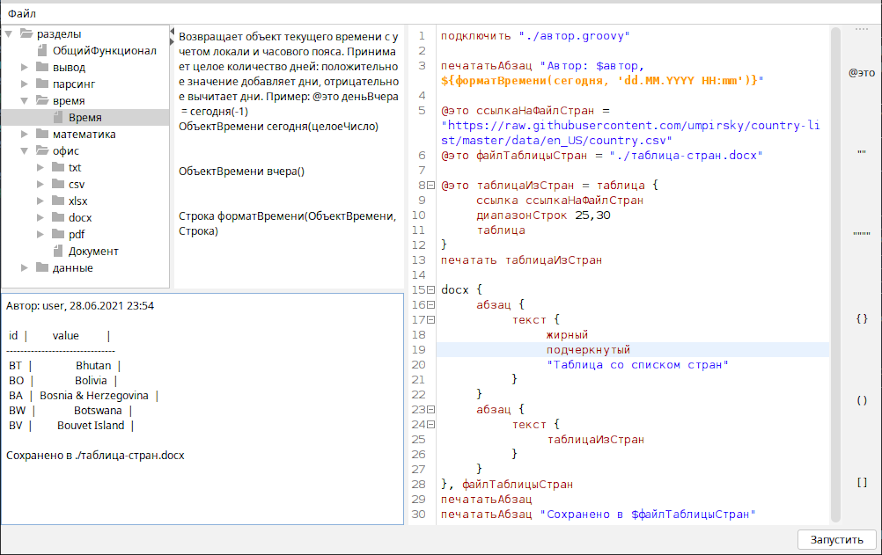
Заметно, что дефолтный вывод tablesaw-таблицы через toString() работает иначе, чем в терминале и промахивается с выравниванием, но это уже частности перехвата вывода скрипта.
Сначала вспомню основные механизмы Groovy, облегчающие работу с DSL-инструментами. Центральный элемент - это, конечно же, Closure, по поведению очень похожее на замыкание в других языках, но это все же объект groovy.lang.Closure и я буду именовать его также:
def closureInstance = { println "Hello, $it!" }
assert closureInstance instanceof groovy.lang.Closure
closureInstance("world")
//Hello, world!
it - implicit parameter, неявный параметр, аналогичное поведение можно было бы получить и определив его явно, например, как { name -> println "Hello, $name!" }. Ключевая особенность у Closure - механизм делегирования, в самом простом случае свойства\методы Closure из DSL-скрипта отображаются тем или иным образом на свойства\методы делегата.
В абстрактном классе Closure определены ссылки на:
- this (thisObject) - класс, в котором определено Closure.
- owner - как и this, но если определение будет вложенное и располагаться в другом Closure, то будет ссылаться на внешнее. this же в этом случае все равно будет указывать на окружающий класс.
- delegate - сначала он указывает на owner, но может быть изменен на другой объект, в котором в зависимости от настроек делегирования будет происходить поиск методов для вызова.
Очередность поиска свойств\методов зависит от стратегий делегирования: вполне понятные по своим названиям Closure.OWNER_FIRST, Closure.DELEGATE_FIRST, Closure.OWNER_ONLY, Closure.DELEGATE_ONLY и Closure.TO_SELF, которое отключает поиск в owner\this, оставляя только объект самого Closure, что в сочетании с наследованием от groovy.lang.Closure должно покрыть те случаи, когда ни одна из других стратегий не подходит. Еще в Closure есть немного функциональщины, но это выходит за рамки данной статьи, да и "функциональные" возможности могут быть относительно условными в чисто объектном языке.
Но само по себе наличие Closure может быть недостаточно, его дополняет Command chains - возможность не писать скобки для инструкций верхнего уровня. DSL фрагмент select column from mytable эквивалентен select(column).from(mytable). Легко заметить, что вызов seleсt должен возвращать какой-нибудь объект (как вариант, Fluent Interface), иметь делегат с методом from и прочие варианты. Есть еще способ реализации через Map, например:
def select = {
print "select $it "
[from: {
print "from $it"
}]
}
def (column, table) = ["mycolumn", "mytable"]
select column from table //select mycolumn from mytable
//т.к. ничего не передаем, то в it будет null, его и распечатает
assert select() instanceof LinkedHashMap
assert select().containsKey("from")
assert select().from instanceof Closure
Данный вариант выглядит немного запутанным, кроме того, он не пройдет static type checking, поскольку метода from у LinkedHashMap фе-факто никакого и нет, но с т.з. динамических фич это выглядит неплохо, очень неплохо.
Более продвинутый вариант - аннотация @DelegatesTo, которую позволяет проходить строгие проверки. Примеры можно найти в документации:
def email(@DelegatesTo(strategy=Closure.DELEGATE_ONLY, value=EmailSpec) Closure cl) {
def email = new EmailSpec()
def code = cl.rehydrate(email, this, this)
code.resolveStrategy = Closure.DELEGATE_ONLY
code()
}
Здесь метод rehydrate внутри клонирует Closure и устанавливает delegate, owner, thisObject соответственно. Можно пожелать вынести все настройки в родительский метод с сигнатурой, например, rehydrateClosure(Closure closure, Object instance), которому можно передать EmailSpec. Такой код будет работать в каких-то ранних версиях 3.0.X, а потом может выдавать ошибку в static type checking из-за несовместимости стратегий: DELEGATE_ONLY в методе выше и OWNER_FIRST (т.к. стратегия в родительском методе не указана, то используется по умолчанию) в родительском. Само по себе наличие таких ошибок намекает на явное прописывание стратегии делегирования, даже если используется стратегия по умолчанию, чтобы потом в случае чего поиском по коду все это можно было бы поменять.
Итого, можно использовать либо фигурные скобки, вкладывая их друг в друга или же ограничиться цепочкой команд. Первое выглядит более интересным из-за поддержки сворачивания блоков кода в разных редакторах, да и структуру чего-либо проще передавать вложенными блоками. Допустим, что нужно определить DSL-шаблон документа, но как тогда обозначать абзацы... вариант
абзац "Абзац 1" абзац "Абзац 2"
выглядит неудобным, редактировать свойства шрифта, цвет, отступы и прочее тут проблематично.
Выходит, что цепочка команд хорошо подходит для запросов (или же CRUD-операций), а вот описание структуры лучше работает с вложенными друг в друга блоками.
С фигурными скобками всё это превращается в:
docx {
абзац {
текст {
//жирный и подчеркнутый - свойства, а не методы
жирный
подчеркнутый
"Абзац 1"
}
}
абзац {
текст {
"Абзац 2"
}
}
}
Важность круглых скобочек повышается и без них Groovy будет пытаться обратиться к свойству "подчеркнутый", а не методу подчеркнутый(). Выглядит тоже не ахти, ибо у сложного документа начинается хаос из {{{{{{{}}}}}}}, но такой вариант явно более гибкий, позволяет сворачивать блоки и переносить их между участками кода. Но что будет, если убрать переносы и написать что-то такое:
абзац {
текст {
жирный подчеркнутый "Это таблица из стран"
}
}
Таки да, получается цепочка команд (если бы там были методы) и свойства "Это таблица..." конечно же нет, можно сделать как-то так:
текст {
жирный() подчеркнутый()
"Это таблица из стран"
}
Но первый вызов должен что-то возвращать, иначе подчеркнутый() попытается вызваться на null. Сразу вспоминаются аннотации на fluent api для возврата this, вроде groovy.transform.builder.Builder, но её стратегии больше подходят именно для билдеров - сеттеры, создания внутренних или внешних билдеров-хелперов. Да и если void-метод внезапно начинает что-то возвращать, то это чревато ошибками с шансом присвоить что-то не так и не туда, а в ином случае хоть ошибка вылетит и остановит этот произвол.
Еще у скобок есть проблема в особенности раскладок и в русскоязычном варианте их нет, нужно постоянно переключать раскладку туда-сюда. Юзабилити может улучшить собственный редактор, в котором скобки и спецсимволы вставляются через Alt\Shift, но если таким редактором пользоваться периодически без привыкания к его "особенностям", то в игру вступает мышечная память при слепой печати и раскладки все равно будут переключаться на автомате, ибо привычно. Технически, более подходящими выглядят круглые скобки (), но подменять синтаксис в DSL мне бы не хотелось, это уже невалидный Groovy-код, что сильно снижает гибкость и возможность запуска его без каких-либо дополнительных обработок.
В самом простом случае работу DSL можно описать так:
- Написание скрипта в файле или редакторе. В нем из {} должны создаваться Closure и отображаться на методы\свойства в делегате.
- Интерпретация его каким-то способом, я использовал GroovyShell. Можно настроить загрузчик классов, биндинг с переменными, дефолтные импорты и т.п. Большая часть из этих настроек потребуется для разных частных случаев и возможностей самого DSL.
- Изменение объекту скрипта DelegatingScript свойства делегата.
- Перехват вывода, если запуск происходит в редакторе, можно сделать через groovy.console.ui.SystemOutputInterceptor.
- Запуск скрипта через run().
Конечно же, выполнение скрипта в основном потоке подвесит редактор, поэтому шаги могут отличаться в зависимости от способа загрузки и выполнения скрипта, особенностей редактора и т.п.
Интуиция подсказывает, что рутовый делегат для DSL-скрипта должен обладать минимальной ответственностью и не пытаться покрыть собой все разделы с математикой, офисом, таблицами и прочим. Его основные задачи - это контроль ошибок, перехват несуществующих свойств (propertyMissing) и управление всеми остальными разделами. На этот случай есть замечательная аннотация @Delegate, которой можно помечать делегаты с разными разделами. Таким образом, добавление и удаление раздела будет сводиться к правке только одного поля в классе. Доступ к списку этих делегатов можно получить рефлексивно, профильтровать по аннотации и устанавливать им рабочие директории, искать в них методы и т.п. Здесь масштабирование очень и очень хорошее.
Вероятно, здесь могут быть конфликты между одинаковым именем методов в разных делегатах и очередностью срабатывания. Поскольку DSL штука сама по себе тяжелая для заучивания и понимания, то есть смысл использовать такую иерархическую структуру делегатов для построения дерева справочной документации. Насколько я знаю, удобного способа дотянуться до комментариев нет, поэтому примеры и документацию проще аннотировать. Кроме справки нужен и вменяемый механизм подсказок при ошибках. Например, если описывается структура ошибочного документа dosx {}, то в рутовом делегате сработает propertyMissing и можно проитерировать методы всех делегатов с поиском подходящих вариантов, выводя предложение корректного варианта 'docx' в тексте ошибки.
Эти требования намекают на смешивание английского и русского, часть Groovy-кода проще написать на русском. Задача начинает сводиться к маскировке английских идентификаторов, хотя такая смесь и не очень хорошо выглядит, но способ вполне рабочий, разве что может быть конфликт с какими-нибудь осями\терминалами и появятся иероглифы из-за проблем кодировок. Теоретически, DSL можно сильно упростить, используя кастомные конструкции, но тогда это уже невалидный Groovy-код со всеми вытекающими, поэтому остается как-то выкручиваться.
Во-первых, нужно определиться с def. С одной стороны, это можно рассмотреть как сокращение от дефиниция, что вполне легально для использования по аналогии с той же математикой и все сильно упрощает. Но это все же эксперимент и в исследовательских целях предположим, что нужно от def избавиться. Здесь можно пойти разными путями, например, вообще его убрать и тогда "переменная" помещается в мапу биндингов, методы доступа к которой определены в groovy.lang.Script:
этоСтрока = "привет, мир"
//true
печатать getBinding().hasVariable("этоСтрока")
печатать getBinding()["этоСтрока"]
Выглядит неплохо и тут напрашивается перехватить несуществующее свойство и проверить наличие его в биндинге, если есть - то это значение переменной, наверное. Из-за этого "наверное" могут быть сложности в отличие переменных от других биндингов, тем более, часть из них могут передаваться скрипту извне с настройками шелла, что может спровоцировать конфликт имен, хотя для инклюдинга такой вариант удобнее. Побочным эффектом будет изменение области видимости:
{
деньСегодня = сегодня()
}
//сработает
печатать деньСегодня
Если очистка мапы с биндингами отсутствует, то между вызовами скрипта могут сохраняться старые переменные. Также есть определенные вопросы к сборке мусора на протяжении работы самого скрипта, разве что пытаться делать коллекцию на слабых ссылках. Еще нужно шарить биндинги между всеми делегатами, которые могут быть вложенными друг в друга, как вариант, пытаться добраться до этих переменных вверх по цепочке this\owner. Есть некая вероятность, что такая логика подмены несуществующего свойства биндингом из другого делегата может привести к неприятным приключениям с какой-нибудь из стратегий делегирования, той же DELEGATE_ONLY. Как видно, недостатков тут хватает, выглядит все это проблемным, но и самым удобным вариантом.
Привлекательно выглядит аннотация @это, как наиболее краткая форма описать все, что угодно, но используя при этом всего лишь три буквы. К ней можно привязать GroovyASTTransformationClass класс для AST-трансформации, где у VariableExpression.setClosureSharedVariable проставить true. Не могу сказать о всех недостатках такого решения, вероятно, могут быть коварные побочные эффекты. Получается что-то такое:
@это деньСегодня = сегодня()
печатать деньСегодня
Судя по AST-дереву там устанавливается тип java.lang.Object, блочная видимость вроде бы сохраняется, изменение значения тоже:
{
@это деньСегодня = сегодня()
}
//не сработает, ошибка
печатать деньСегодня
@это будущееДва = 1
будущееДва += 1
//2
печатать будущееДва
Недостаток - символа at (@) в русской раскладке обычно нет, с другой стороны, нет и того же $ для удобной интерполяции переменных в строках. Еще здесь возникает сразу несколько вопросов. Во-первых, без надоедливых скобочек() Groovy будет рассматривать "сегодня" как свойство, а не метод. Это легко исправить методом перехвата несуществующего свойства, например, через propertyMissing и попробовать вызвать вместо него нужный метод. Но тогда выходит, что метод и свойство ведут себя одинаково и между ними может быть конфликт. С другой стороны, такие скобки явно неудобны, наличие конфликтующего свойства можно проверить дополнительно и я остановился на варианте с перехватом. В итоге, если есть редирект со свойства на метод будет:
@это деньСегодня = сегодня
//или же можно сразу
печатать сегодня
Второй вопрос, в какой форме глагола удобнее представлять действие, например, это может быть "печать". С другой стороны, печать больше подходит для описания структуры, что-то вроде:
печать {
принтер 1
}
Но здесь происходит еще и смешение смыслов - печать на принтере и печать в терминале, но можно условно допустить, что печать происходит где-то, а печатающее устройство вывода может быть любым и здесь глагол 'печатать' как аналог print выглядит вполне легально. Нужно учитывать, что может быть несколько вариантов этого метода, как и print\println. Русский язык в качестве программного сам по себе многословен и 'печататьСпереносом' в CamelCase нотации выглядит плохо. Более интересен вариант 'печататьАбзац', хотя абзац может подразумевать и красную строку как отступ.
Если вместо 'печатать' взять глагол 'сообщить' из 1С, то форма 'сообщитьАбзац' выглядит немного странно, но терпимо. С другой стороны, русскоязычные методы через print\println работают с PrintWriter, например, при надлежащей реализации можно вызывать их в описании структуры офисного документа, что немного уходит от смысла глагола 'сообщить'. Но опять-таки, смотря с какой стороны на это посмотреть, ведь смысловое содержание можно трактовать по-разному, например, как пересылка сообщения.
Раз def "заменяет" аннотация, то для выполняемого скрипта требуются дефолтные импорты для неё, что можно сделать через org.codehaus.groovy.control.customizers.ImportCustomizer, который добавляется в org.codehaus.groovy.control.CompilerConfiguration.
Еще один вариант - использовать метки. До метки можно дотянуться через CompilationCustomizer, переопределяя у визитора (ClassCodeVisitorSupport и т.п.) visitExpressionStatement (или же более общий метод visitStatement) и проверяя getStatementLabels, получается как-то так:
это: деньСегодня = сегодня
Теоретически, можно попытаться убрать и двоеточие, использовав цепочку вызовов, пустой метод-заглушку или что-то через кастинг (если убрать двоеточие у метки, то будет GroovyCastException), получая 'это деньСегодня = 1', но разбор будет идти справа налево и добраться до VariableExpression тут может быть сложнее, начинаются уже какие-то костыли. Вариант с меткой выглядит наиболее привлекательным, но у него возникли определенные проблемы с областью видимости из блока Closure (в самом скрипте работает более-менее корректно) и AST-трансформация с at сработала более стабильно.
Используя кастомайзеры можно решить и другую проблему - инклюдинг или же включение скриптов друг в друга. Для задач конфигурации скрипты просто перезаписывают свойства друг друг и никакой особой игры руками не требуется. Но если не используется запись переменных в мапу биндингов, то по смыслу инклюдинга нужен доступ к переменным (и не только), определенным во включаемом скрипте. В мапу с биндингами они не добавляются, в properties объекта скрипта их тоже нет. Если погуглить, то можно найти решение, однако PrimaryClassNodeOperation и т.п. все уже deprecated. Еще один вариант: у CompilerConfiguration есть метод addCompilationCustomizers, куда можно добавить свой кастомный от ClassCodeVisitorSupport и вызвать визитор. Для доступа к переменным все же лучше переопределять visitDeclarationExpression и там дотянуться до имени переменной и его значения.
Наверное, самый простой способ - собрать эти переменные в коллекцию и позже поискать в ней несуществующее в скрипте свойство. Но такой подход не делает переменные глобальными для всех участков кода: если обращение к ним будет в другом Closure, которое определяется в скрипте, то нужно расшаривать коллекцию с переменными или же выкручиваться как-то еще, например, через делегирование. Конечно же, чтобы во включаемом скрипте работали все разделы, нужно установить делегат со всеми методами\свойствами как и у включающего скрипта.
Еще неплохо было бы иметь дефолтную рабочую директорию, в которую по умолчанию складываются выводы разных команд, сохраняются документы и т.п. Для архитектуры выше это не представляет особых проблем и главный скрипт управляет списком делегатов, устанавливая им эту директорию, либо же обратным вызовом работает с ней. Раз есть состояние, то нужен и метод для распечатывания этой директории и прочей служебной информации. Кроме того, для редактора её можно вывести в тайтл окна, чтобы наверняка.
Конечно же, любой DSL должен хорошо отлаживаться, а в Groovy есть замечательный assert. Один из вариантов его использования - это поместить выражение в строку и выполнить с assert в groovy.util.Eval, хотя это нельзя назвать нормальным:
@это один = 1
@это два = 2
проверить "$один > $два"
//вывод:
assert 1 > 2
|
false
Можно заменить английские слова, добавить номер строки и т.п. но сама строка с условием тут выглядит явно неудобной и есть определенные проблемы от Eval, которая может выполнить все, что угодно и создать массу побочных эффектов и ошибок. Возможно, более лучшим вариантом будут AST-аннотации, но чтобы пометить аннотацией выражение нужен какой-нибудь более извращенный ElementType.TYPE_USE со скобочками, кгм...но тогда становится неудобной сама конструкция.
Есть еще один вариант - через метки, но это все же не метод и логично "проверить" заменить на "проверка":
проверка: 1 > 2
Это вносит в синтаксис определенную неконсистентность: здесь логично ожидать обычный вызов или аннотацию, а не метку, это все немного усложняет, что где и когда использовать. Еще появляется много частных случаев, например, "$один > $два" это уже GStringExpression, 1 > 2 это уже ConstantExpression (вернее два - левое и правое). Мне кажется, что это тот случай, когда assert проще использовать напрямую, не маскируя, а для выброса ошибок придумывать что-то другое, хотя и не факт.
Определенный интерес вызывают базовые конструкции языка и здесь можно вдоволь поэкспериментировать с метапрограммированием. Интерес скорее более теоретический, все же чем больше функционал сближается с языком программирования, тем больше хаков потребуется для скрытия английского и подстраивания DSL под особенности Groovy, что выглядит как бодание с языком и ненужное усложнение. Но все же, например, интересно выглядят методы обхода итерируемых объектов с перенаправлением на each. Можно добавить подобные методы через метакласс (возможно, можно сделать еще и через указатель на метод &):
Iterable.metaClass.обойти = { delegate.each(it) }
[4, 6, 3].обойти { элемент ->
//или же как печататьАбзац it
печататьАбзац элемент
}
Но и тут закрадывается неконсистентность: если в вызове "печатать что-то" глагол стоит на первом месте, то логично ожидать этого и от обхода. Можно заменить обычным методом, который принимает итерируемую цель и Closure, тогда за счет цепочки команд получится так:
обойти (0..2) { число ->
печататьАбзац число
}
//однако
обойти ([4, 6, 3]) { элемент ->
печататьАбзац элемент
}
Как видно, если во втором варианте определить список, то "обойти" будет воспринято как свойство и нужны дополнительные скобки, что такое себе. Можно создать замену, например, для if...else, где в самом простом случае достаточно двух Closure, которые вызываются в зависимости от булевого результата, цепочка команд получается такой:
если(2 > 3) {
печатать "больше"
} {
печатать "меньше"
}
//меньше
что эквивалентно если((2 > 3),{ печатать "больше" },{ печатать "меньше" }), хотя если добавлять else if, метки то...иначе и т.п., то все может усложниться, да и само по себе такое добавление замен для всех конструкций выглядит очень сомнительной затеей.
Смешивание Groovy-кода и DSL позволяет использовать какую-то часть языка напрямую, например, оператор умножения для строк перегружен и можно сделать что-то вроде печататьАбзац "*" * 10, что напечатает **********.
Тесно связана со скриптами безопасность: под капотом полноценный язык программирования, где запросто можно заставить пользователя как-то запустить вредоносный код (или он сделает это специально) или же сделать какую-нибудь ошибку. Самый простой вариант перехвата вызовов методов через groovy.lang.Interceptor (или же через метапрограммирование) в сложных случаях могут подвести, разве что предупреждать о каких-то опасных вызовах в самом DSL, стараясь предотвратить пользовательские ошибки. Об особенностях SecureASTCustomizer можно посмотреть здесь, как и о разных вариантах реализации песочниц, но тут не могу сказать, изменилось ли что-то в самом груви с новыми версиями или же нет. Построение надежных песочниц выглядит задачей нетривиальной, с массой нюансов.
Кроме того, ввод от пользователя может быть подвержен разного рода ошибкам, тем же опечаткам и в части арифметики, как и у Java, можно случайно получить молчаливое переполнение (например, если число будет скопировано и случайно вставлено несколько раз подряд), никакого исключения при этом не будет:
println Integer.MAX_VALUE
//2147483647
def result = Integer.MAX_VALUE + 1
println result.dump()
//<java.lang.Integer@80000000 value=-2147483648>
result = Integer.MAX_VALUE + 1.0
println result.dump()
//<java.math.BigDecimal@12c6 intVal=null scale=1 precision=0 stringCache=null intCompact=21474836480>
println result as int
//-2147483648
println result as long
//2147483648
//здесь вылетит java.lang.ArithmeticException: integer overflow
println Math.addExact(Integer.MAX_VALUE, 1)
Что касается переполнения при возведении в степень, то сработает автокаст:
(10**100).dump()
//java.math.BigInteger@edfefc9e signum=1 mag=[4681, -1390046013, 2095778599, -2067476981, -209007040, -1910433156, -1431158008, -1473343728, 0, 0, 0] bitCountPlusOne=0 bitLengthPlusOne=0 lowestSetBitPlusTwo=0 firstNonzeroIntNumPlusTwo=0>
Теоретически, пользователя может удивить даже результат от специальных значений IEEE 754, что есть смысл тоже учитывать, ведь за счет использования чистого Groovy он может запросто может их получить. Хотя Groovy делить на нуль не позволяет даже числа с плавающей точкой и 1.0/0 выдаст не Infinity, а java.lang.ArithmeticException: Division by zero.
Конечно же, злую шутку могут сыграть локалезависимые операции, например, парсинг числа с плавающей точкой или же его форматирование.
//3.14
println "3.14" as Double
//java.lang.NumberFormatException: For input string: "3,14"
println "3,14" as Double
При очень редком стечении обстоятельств это может создать коварные баги, например, при парсинге массива из строки, в которой элементы разделены запятыми. Если пользователь вставит число "3,14", то оно превратится в массив [3, 14], а не [3.14]. Если в расчетах будет участвовать первый элемент массива, то за счет небольшой дробной части эту ошибку можно долго не замечать.
В целом, эксперимент можно признать очень интересным и частично успешным. Недостаток - производительность, особенно инициализация, в static type checking это очень долгий процесс. Уже запущенный редактор работает по скорости более-менее терпимо, если потребуется многократно запускать скрипты, то можно поднять сервер\службу и т.п.
Русский язык очень сильно осложняет задачу и, несмотря на всяческие маскировки, малой кровью полностью от английского избавиться маловероятно. С одной стороны, разработка на другом языке скорее задача нестандартная, но она вскрывает потребность в гибкой настройке разных особенностей DSL и этой гибкости хотелось бы побольше.
С другой стороны, какая-то смесь языков вполне терпима, все же основное - это специализированные термины. Если же пытаться локализовать все конструкции языка, то объем работ увеличивается и польза от такого DSL уже выглядит сомнительной - он переусложняется, постепенно превращаясь в язык программирования. Пользователь, не знакомый с программированием будет испытывать тем больше сложностей, чем больше DSL становится похож на программирование, а высокая сложность может резко снизить полезность всей затеи, что проще будет взять какой-нибудь язык программирования и обойтись без лишней возни с DSL.